


Caching, an ingenious technique rooted in the early days of computing, has played a pivotal role in optimizing the performance of software systems. In this comprehensive guide, we delve into the intriguing history of caching, explore its evolution, touch upon the initial methods employed, and shine a spotlight on the three most common cache systems Redis, Memcached, and Couchbase. Along the way, we navigate the intricacies of cache eviction policies, offering insights into their importance and discussing the most commonly used policies.
Arthur Burks and Herman Goldstine were crucial figures in developing the Electronic Numerical Integrator and Computer (ENIAC), one of the first electronic general-purpose computers.
In 1946, Burks and Goldstine recognized that the speed of the computer’s operations was limited by the time it took to access the main memory, which was a slow and cumbersome process. To address this problem, they proposed the use of a small high-speed memory unit, which they called a “cache”, that could hold frequently used data and instructions closer to the processor for faster access.
The Genesis: A Need for Speed
The Early Days: Overcoming Hardware Limitations
- The origin of caching can be traced back to the 1950s when early computers grappled with limited memory and processing power. In 1951, the UNIVAC I, one of the earliest commercially produced computers, employed a form of caching by utilizing a mercury delay line memory to store frequently accessed data. This marked the inception of the caching paradigm, driven by the inherent challenge of accessing data from slower memory sources, such as hard disks, which proved time-consuming and computationally expensive.
Local Caching: A Simple Beginning
- Initial caching methods were uncomplicated, with local caching emerging as a primary approach. In the 1960s, as computers evolved, the concept of cache memory started to gain prominence. IBM’s System/360, introduced in 1964, featured a multi-level storage hierarchy with cache memory situated between the central processing unit (CPU) and main memory. Copies of frequently accessed data found a home in faster memories like cache memory or registers. This local caching method was a crucial step in enhancing real-time applications’ responsiveness, such as flight simulations and early video games.
The Evolution: A Symphony of Caches
Cache Hierarchy: Rising Above the Ordinary
- As the use of caching expanded, the 1970s witnessed the advent of cache hierarchies. In 1978, the CDC Cyber 205 supercomputer employed a multi-level cache system, incorporating both primary and secondary caches. Cache hierarchy became the norm, introducing multiple levels of caching to improve overall system performance. With the CPU cache at the top, followed by the L2 cache and main memory, this hierarchical approach allowed systems to access frequently used data from progressively faster memories.
During the early days of caching in the 1960s and 1970s, cache management was relatively straightforward. Systems employed basic algorithms to decide which data to keep in the cache. However, as memory systems evolved, there was a growing need for more sophisticated eviction policies.
1980s: A Decade of Microprocessor Cache Integration
- In the 1980s, microprocessor cache integration became a focal point. Intel introduced the 8086 processor with an integrated 4KB memory cache in 1982. As microprocessors evolved, on-chip caching became standard, paving the way for faster data access.

- In the 1980s, as systems grappled with the increasing complexity of cache management, the Least Recently Used (LRU) policy emerged as a time-tested strategy. This policy prioritized keeping in the cache the data that had been accessed most recently, assuming that this data was more likely to be accessed again soon. LRU became a stalwart in cache eviction policies, providing a practical and effective approach to managing cache content.
1990s: The Rise of Web and Content Caching
- With the rise of the World Wide Web in the 1990s, web and content caching gained prominence. Content Delivery Networks (CDNs) emerged, utilizing distributed caching servers worldwide to reduce latency and accelerate content delivery. This era marked a significant shift towards caching not only at the hardware level but also at the application and network levels.
As computing systems advanced through the 1990s, refinements and variations of eviction policies, including LRU, started to appear. Researchers and practitioners experimented with modifications to improve the adaptability of caching strategies to different application scenarios. Although LRU maintained its popularity, this period saw the exploration of variations like Least Frequently Used (LFU) and Most Recently Used (MRU) policies.
The 2000s: Distributed Caching and the Era of Scalability
- The 2000s witnessed the proliferation of distributed systems, and caching became integral to achieving scalability. Memcached, an open-source distributed memory caching system, was released in 2003, providing a simple yet powerful caching solution for web applications. This era also saw the rise of dynamic websites and applications, emphasizing the need for efficient caching strategies.
Memcached, a free and open-source distributed memory caching system, plays a crucial role in optimizing web application performance.
What is Memcached?
Imagine a high-speed storage space specifically designed to hold frequently accessed data. Memcached acts as this storage, residing in RAM (Random Access Memory) and offering lightning-fast retrieval compared to traditional databases.
Core Functionalities:
Caching: Memcached stores key-value pairs, where the “key” acts as a unique identifier for the data (often an ID or string), and the “value” represents the actual data being cached (like database query results, API responses, or session information). By serving cached data, Memcached alleviates pressure on the primary database, allowing it to focus on critical operations.
High Performance: By storing data in RAM, Memcached boasts significantly faster retrieval times compared to disk-based databases. This translates to quicker response times for web applications. Faster data retrieval from RAM translates to quicker page load times and improved user experience.
Scalability: Memcached can be deployed across multiple servers, distributing the cache load and enabling horizontal scaling for handling increased traffic. Distribution across multiple servers ensures Memcached can handle growing traffic demands.
Memcached has found widespread adoption across industries, from social media giants to e-commerce platforms. For instance, Facebook relies on Memcached to cache user profiles and feed data, enhancing the responsiveness of its platform. Similarly, Amazon leverages Memcached to cache product listings and shopping cart data, ensuring a seamless shopping experience for millions of users. As I delved into Memcached, I encountered its minimalist approach to caching, which can be both a blessing and a curse. While Memcached’s simplicity accelerates development and deployment, it also imposes limitations on data structures and query capabilities. Overcoming these constraints requires a nuanced understanding of Memcached’s strengths and trade-offs. Below is a basic code snippet to show how to store and access data from Memcached.
const Memcached = require('memcached');
// Connect to Memcached server
const memcached = new Memcached('127.0.0.1:11211');
// Set a value
memcached.set('key', 'Hello, Memcached!', 3600, (err) => {
if (err) {
console.error('Error setting value:', err);
return;
}
console.log('Value set successfully');
});
// Retrieve a value
memcached.get('key', (err, data) => {
if (err) {
console.error('Error getting value:', err);
return;
}
console.log('Retrieved value:', data);
});
// Delete a value
memcached.del('key', (err) => {
if (err) {
console.error('Error deleting value:', err);
return;
}
console.log('Value deleted successfully');
});
// Error handling
memcached.on('issue', function (details) {
console.error("Issue occurred:", details);
});
// Set a value with expiration time (in seconds)
memcached.set('key1', 'Hello there, Memcached!', 60, function (err) {
if (err) {
console.error('Error setting value:', err);
return;
}
console.log('Value "key1" set successfully');
});
// Set multiple values at once
const items = [
{ key: 'key2', val: 'Value 2' },
{ key: 'key3', val: 'Value 3' }
];
items.forEach(item => {
memcached.set(item.key, item.val, 60, function (err) {
if (err) {
console.error(`Error setting value for key ${item.key}:`, err);
return;
}
console.log(`Value "${item.key}" set successfully`);
});
});
// Get a value
memcached.get('key1', function (err, data) {
if (err) {
console.error('Error getting value:', err);
return;
}
console.log('Retrieved value for "key1":', data);
});
// Get multiple values at once
memcached.getMulti(['key1', 'key2', 'key3'], function (err, data) {
if (err) {
console.error('Error getting multiple values:', err);
return;
}
console.log('Retrieved values:', data);
});
// Delete a key
memcached.del('key1', function (err) {
if (err) {
console.error('Error deleting key:', err);
return;
}
console.log('Key "key1" deleted successfully');
});
// Flush all data from Memcached
memcached.flush(function (err) {
if (err) {
console.error('Error flushing data:', err);
return;
}
console.log('Memcached flushed successfully');
});
// Close Memcached connection
memcached.end();
- In the 2000s, the focus shifted towards adaptive policies that dynamically adjusted their behavior based on the changing access patterns of data. These policies aimed to enhance cache efficiency by responding to the evolving nature of workloads. Adaptive algorithms, inspired by machine learning principles, started making their way into cache management systems.
2010s: Redis and In-Memory Databases Take Center Stage
- In 2010, Redis gained widespread popularity as an advanced key-value store and caching solution. Its in-memory data storage and support for various data structures made it a versatile choice for developers. We will dive deep into it in just a minute. The 2010s also saw the increased adoption of in-memory databases like Apache Cassandra and MongoDB, which inherently leveraged caching mechanisms for rapid data access.
Redis: The In-Memory Marvel
Redis stands as a beacon of efficiency and versatility in the caching landscape. Born from the need for lightning-fast data access, Redis boasts an in-memory data store and a rich set of data structures. Let’s take a closer look at what sets Redis apart:
Under the Hood: Redis operates on a simple yet powerful premise: storing data in memory for rapid access. But its true magic lies in its support for various data structures, including strings, hashes, lists, sets, and sorted sets. This flexibility enables Redis to cater to a diverse range of use cases, from caching to real-time analytics and beyond.
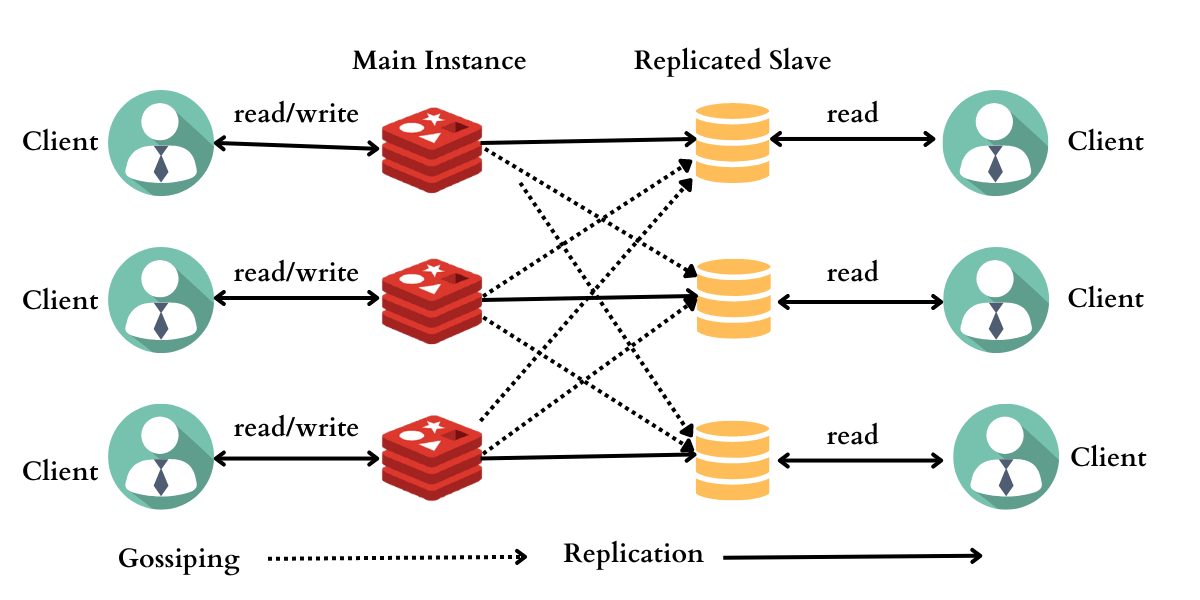
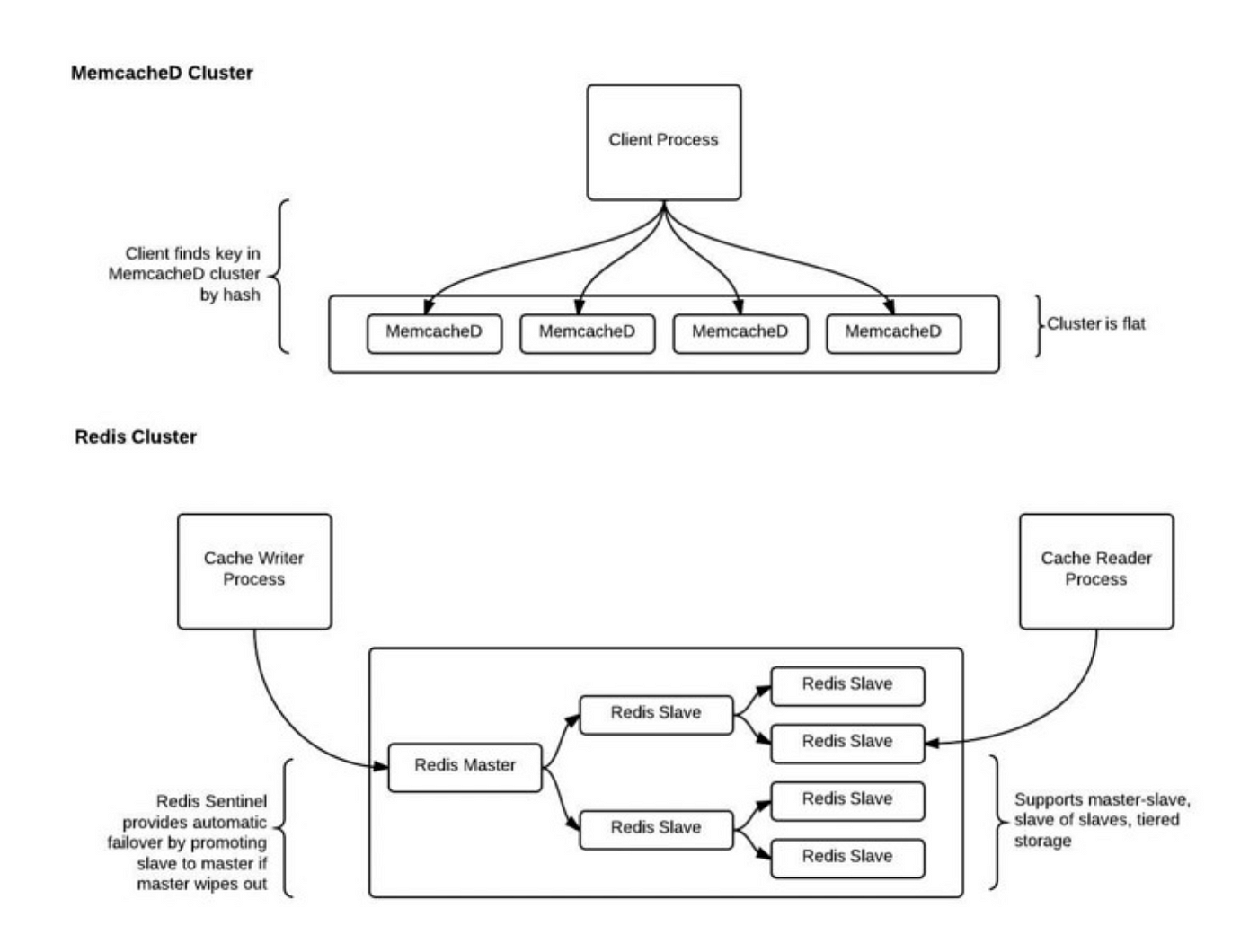
Scaling Like a Boss: Redis in a Cluster
As your application grows, a single Redis instance might not suffice. Fortunately, Redis offers horizontal scaling capabilities through clustering. This allows you to distribute data across multiple servers, improving performance and redundancy.
There are two main clustering architectures:
Master-Slave Replication: One server acts as the master, accepting all writes and replicating data to slave servers. This provides high availability but can have limitations on write throughput.
Cluster with Redis Sentinel: This more complex setup involves multiple masters and slaves, with Redis Sentinel automatically managing failover and ensuring high availability.
Persistence: Keeping Your Data Safe(ish)
By default, Redis is an in-memory data store, meaning data is lost when the server restarts. However, Redis offers persistence options to mitigate this. The two main approaches are:
RDB (Redis DataBase): Periodically snapshots of the entire dataset are saved to disk. This allows for faster recovery but might lead to some data loss if a failure occurs between snapshots.
AOF (Append-Only File): Every write operation is logged to a file. This ensures data durability at the expense of slightly slower recovery times.
Choosing the right persistence option depends on the application’s specific needs for data durability versus performance.
Unleashing the Power of Lua Scripting
Redis goes beyond simple data storage by allowing you to execute Lua scripts within the server. This enables powerful functionalities like:
Implementing custom logic for data manipulation within Redis.
Building complex data processing pipelines.
Triggering actions based on specific events.
While the core functionality of Redis is accessible without scripting, Lua unlocks a new level of customization and automation. Redis finds its place in the tech stacks of countless companies, powering critical components of their infrastructure. For example, Twitter employs Redis to manage its timeline cache, ensuring timely delivery of tweets to millions of users worldwide. Similarly, GitHub relies on Redis for caching repository data, speeding up code access and collaboration for developers. While Redis’s simplicity may seem inviting, mastering its full potential requires a deep understanding of its features and nuances. As I embarked on my Redis journey, I encountered the issue of unexpected crashes and downtime because I underestimated Redis’s memory requirements. This underscores the importance of careful planning and resource management when integrating Redis into your architecture. Remember, Redis is a powerful tool, but it’s not a one-size-fits-all solution. Here is a basic code showcasing the Redis connection using Node.js and how to access and store data.
const redis = require('redis');
// Connect to Redis
client = redis.createClient({ url: 'redis://localhost:6379'});
(async () => {
await client.connect();
})();
// Set a key-value pair
client.set('key', 'value', (err, reply) => {
if (err) {
console.error(err);
} else {
console.log('Key set successfully:', reply);
}
});
// Retrieve value by key
client.get('key', (err, value) => {
if (err) {
console.error(err);
} else {
console.log('Retrieved value:', value);
}
});
While both Redis and Memcached are memory-based caching systems, Redis offers additional features like data structures and persistency, making it suitable for broader use cases.
- The 2010s witnessed the rise of hybrid eviction policies like LRU-K Hybrid Policy, and Two Queue Policy that combined elements of multiple strategies. Moreover, machine learning-driven policies gained traction, leveraging algorithms to predict future access patterns and optimize cache decisions. This era marked a departure from traditional static policies, as systems began to incorporate more intelligent and dynamic approaches
2020: Caching in the Modern Era
As of 2020, caching remains a critical component in optimizing software performance. Modern applications, especially those in microservices architectures and cloud environments, rely heavily on caching to manage data at scale. The landscape includes not only traditional solutions like Redis but also cloud-native caching services offered by major cloud providers, further streamlining the integration of caching into diverse software ecosystems.
In the modern era, cache eviction policies continue to evolve. With the growth of diverse application architectures, there’s an increasing emphasis on customization. Developers often tailor eviction policies to specific use cases, considering factors such as data access patterns, system resources, and workload characteristics. The flexibility and adaptability of modern cache systems allow for a wide range of eviction policy implementations, making them a crucial component in optimizing software performance.
Couchbase, a NoSQL document database, caters to modern application needs by offering a unique blend of high performance, scalability, and flexibility. Imagine a database that seamlessly blends the power of document-oriented and key-value data storage. Couchbase operates on this principle, allowing you to store and retrieve data in flexible JSON documents while maintaining efficient key-based access.
Core Functionalities:
Document-Oriented Storage: Data is stored as JSON documents, enabling the representation of complex data structures with nested objects and arrays. This aligns well with modern application development approaches. The document-oriented approach caters to evolving data models and facilitates the storage of diverse data types.
Key-Value Access: Efficient retrieval of specific data elements is possible using unique keys, ensuring quick access to frequently used information. The combination of in-memory caching, key-value access, and distributed architecture ensures lightning-fast data retrieval.
High Performance and Scalability: Couchbase leverages a distributed architecture, enabling horizontal scaling across multiple servers. This translates to handling massive datasets and high traffic volumes efficiently. Horizontal scaling capabilities allow Couchbase to seamlessly adapt to increasing data volumes and user base.
ACID Transactions: Couchbase offers strong consistency guarantees through its implementation of Multi-Document ACID (Atomic, Consistent, Isolated, Durable) transactions. This ensures data integrity during concurrent operations. ACID transactions guarantee data integrity, crucial for maintaining application reliability.
Built-in Caching: Frequently accessed data can be cached within the database itself, further reducing latency and improving response times.
Enterprises across industries have embraced Couchbase for its scalability, performance, and data modeling capabilities. For example, PayPal relies on Couchbase to power its fraud detection systems, leveraging its distributed caching and strong consistency guarantees. Similarly, LinkedIn employs Couchbase to manage user profiles and network data, ensuring a responsive user experience for millions of professionals.
const couchbase = require('couchbase');
// Couchbase configuration
let cluster;
let bucket;
let collection;
async function init (){
cluster = await couchbase.connect('couchbase://localhost', {
username: 'admin',
password: '*******',// write you password for the cluster
})
bucket = cluster.bucket('temp_bucket');
collection = bucket.defaultCollection();
}
// Function to insert a document
async function insertDocument() {
try {
const result = await collection.insert('document_key', { name: 'John', age: 30 });
console.log('Document inserted:', result);
} catch (error) {
console.error('Error inserting document:', error);
}
}
// Function to retrieve a document
async function getDocument() {
try {
const result = await collection.get('document_key');
console.log('Retrieved document:', result.value);
} catch (error) {
console.error('Error getting document:', error);
}
}
// Function to update a document
async function updateDocument() {
try {
const result = await collection.replace('document_key', { name: 'John Doe', age: 35 });
console.log('Document updated:', result);
} catch (error) {
console.error('Error updating document:', error);
}
}
// Function to delete a document
async function deleteDocument() {
try {
const result = await collection.remove('document_key');
console.log('Document deleted:', result);
} catch (error) {
console.error('Error deleting document:', error);
}
}
// Call init function to establish connection
init().then(() => {
// Perform operations after initialization
insertDocument();
getDocument();
updateDocument();
deleteDocument();
});
I encountered its robust feature set and complex deployment options. While Couchbase’s rich functionality offers unparalleled flexibility, configuring and managing a Couchbase cluster can be daunting. However, with careful planning and expertise, Couchbase empowers developers to build scalable and resilient applications.
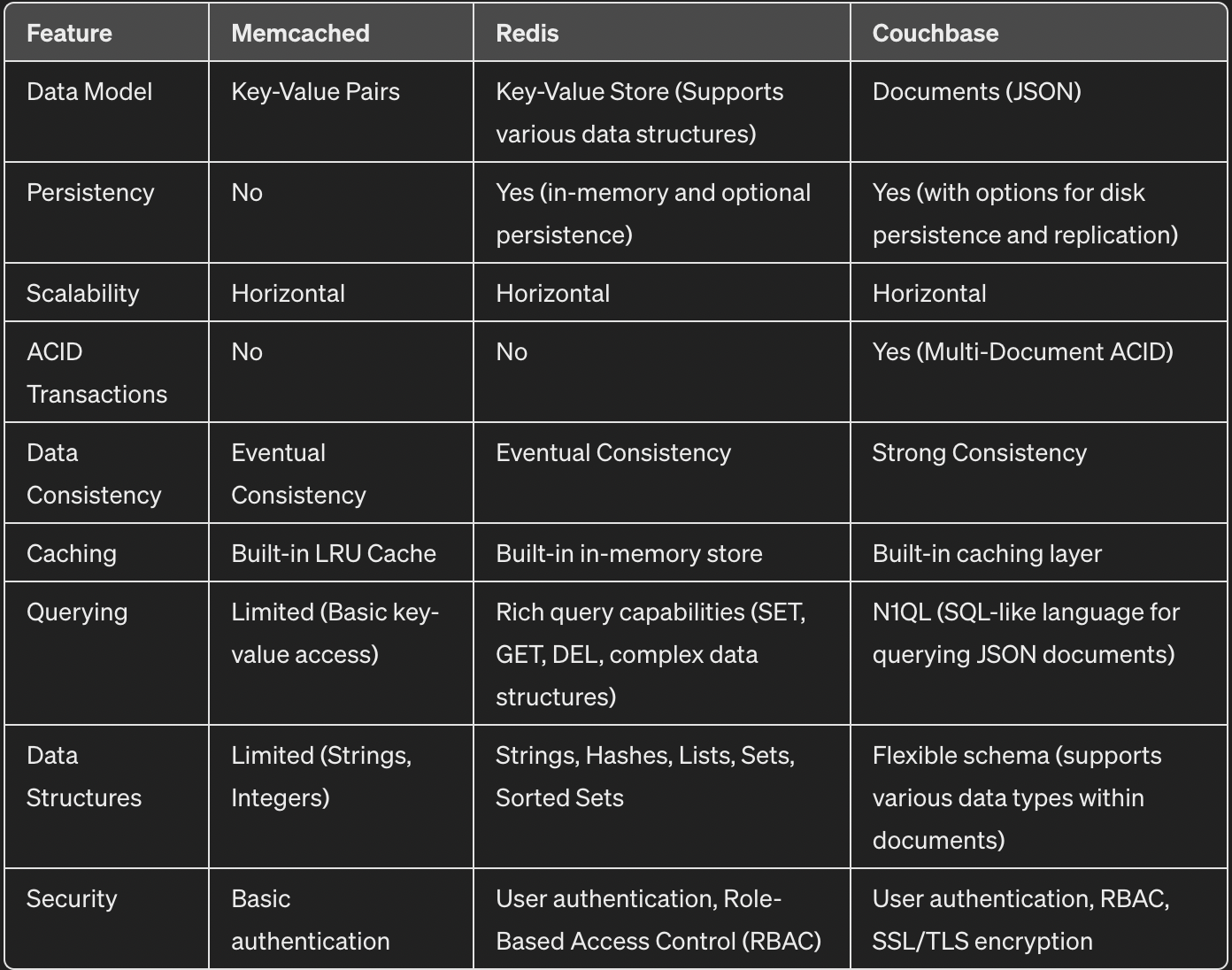
Here is a comparative chart of Redis, Memcached, and Couchbase
Caching in Action: Across Different Fields
Web Development:
Content Delivery: Caching accelerates web content delivery by storing static assets, reducing server load, and improving page load times.
Session Data: Caching user sessions enhances web application responsiveness and user experience.
Database Systems:
Query Results: Caching query results reduces database load and speeds up data retrieval for frequently requested queries.
Object-Relational Mapping (ORM): Caching frequently accessed objects improves overall application performance in ORM systems.
Distributed Systems:
Microservices Communication: Caching helps alleviate the load on micro-services by storing frequently requested data, enhancing system scalability.
API Responses: Caching API responses reduces latency and improves the overall responsiveness of distributed systems.
E-commerce:
Product Listings: Caching product listings and details improves the speed of e-commerce websites, providing a seamless shopping experience.
Shopping Cart: Caching shopping cart data enhances transaction speed and ensures a smooth checkout process.
While specific benchmark numbers can vary based on factors like system architecture, data size, and workload characteristics, caching has consistently demonstrated significant performance improvements. In web development, caching static assets can lead to a reduction in page load times by up to 50% or more. Database query caching has shown speed improvements ranging from 10% to 100%, depending on query complexity and frequency.
Conclusion: A Legacy of Optimisation
Caching, a timeless technique, has seamlessly evolved from its humble beginnings to become a sophisticated tool for software optimization. With its in-memory prowess and versatile eviction policies, Redis continues to be a cornerstone in the caching realm. There are many technologies, which are discussed above (but not limited to) that are pushing the limits and evolving. As we navigate through the dynamic landscape of software engineering, caching stands tall as a testament to the industry’s relentless pursuit of efficiency and speed.